
Processo di pubblicazione sugli open data¶
Metodologia per la pubblicazione dei dati in formato open¶
La metodologia per la pubblicazione dei dati in formato Open Data fa riferimento al modello operativo discusso precedentemente e si pone l’obiettivo di pianificare le azioni da intraprendere per raggiungere la pubblicazione dei dati a 5 stelle, secondo la classificazione presentata in Appendice B. Questo obiettivo si raggiungerà per passi individuando un primo sotto-obiettivo nella pubblicazione dei dati a 3 stelle, per poi passare gradualmente alle 5 stelle. Ovviamente affinché il processo sia efficiente occorre progettarlo tenendo in considerazione fin dall’inizio l’obiettivo finale della pubblicazione dei dati a 5 stelle.
Ad oggi la maggior parte dei dataset sono pubblicati con formato catalogabile a 3 stelle.
La metodologia proposta si basa sulle metodologie descritte nelle “Linee Guida per l’Interoperabilità Semantica attraverso i Linked Open Data” pubblicate dall’agenzia per l’Italia Digitale e nel documento di Villazón-Terrazas “Methodological guidelines for publishing linked data”. Entrambi i documenti individuano azioni specifiche che occorre intraprendere affinché i dati della pubblica amministrazione possano essere pubblicati come Linked Open Data.
L’approccio che verrà seguito riprende al suo interno le fasi previste dalle metodologie citate, ma differisce da queste in quanto si prevede una milestone intermedia relativa alla pubblicazione dei dati in formato a 3 stelle, per consentire una prima valorizzazione dei dati pubblicati attraverso la realizzazione di applicazioni specifiche. Nelle fasi successive verranno intraprese le azioni necessarie per la pubblicazione dei dati in formato Linked Open Data. Il seguente elenco mostra i passi dell’approccio proposto:
- individuazione e selezione dei dataset negli uffici;
- bonifica dei dataset ove si ritenga necessario per il rispetto dei requisiti minimi per la pubblicazione;
- arricchimento tramite metadati ai sensi dello standard DCAT_AP_IT 2016;
- validazione e pubblicazione (dati almeno 3 stelle);
- analisi e modellazione;
- linking con dataset esterni;
- validazione e pubblicazione (dati a 4 e 5 stelle).
Modalità di individuazione (e selezione) dei dati da pubblicare in formato open¶
Saranno oggetto di pubblicazione in formato aperto, tendenzialmente, tutti i dati e i documenti contenenti dati che il Comune di Palermo ha acquisito o prodotto nell’ambito dell’esercizio delle proprie funzioni istituzionali e di cui il medesimo è titolare, o di cui è nella piena disponibilità anche tenendo conto (ma non limitatamente) della normativa vigente in tema di pubblicazione di dati in formato aperto e del rispetto della privacy degli individui.
A tale proposito viene effettuato, attraverso i Dirigenti e/o i referenti open data di Settore, Servizio o Unità Organizzativa, un censimento delle raccolte di dati create dalle strutture comunali in funzione delle competenze specifiche e delle attività relative. A ogni Dirigente e alla Società comunale dei servizi informatici SISPI SpA viene chiesto di compilare una scheda, anche online, per ogni raccolta di dati che ne individui la tipologia, il formato, il livello di privacy, l’ubicazione, la data di creazione, la data dell’ultimo aggiornamento, ecc. (vedi scheda in Appendice C). Il team Open Data, durante le riunioni periodiche, esamina le raccolte di dati e ne individua la priorità di pubblicazione (in funzione della pubblica utilità, ecc.).
Nel primo periodo di attuazione dei contenuti delle Linee Guida comunali open data approvate con Deliberazione di Giunta Municipale n. 252 del 13.2.2013, per avviare il processo di pubblicazione dei dataset comunali, è stata seguita la procedura del metodo MoSCoW di seguito schematizzato.
| Priorità | Descrizione | Fattori identificativi |
|---|---|---|
| M - MUST | Indica un dataset che ha la massima priorità di pubblicazione affinché il servizio Open Data possa essere considerato un caso di successo. | Ampio interesse per il dataset da parte della collettività. Best Practice in altre PA |
| S - SHOULD | Indica un dataset ad alta priorità che, se possibile, dovrebbe essere incluso nella lista di pubblicazione attuale. | Medio interesse per il dataset da parte della collettività. Pubblicato da altre PA |
| C - COULD | Indica un dataset che si ritiene di auspicabile pubblicazione ma non necessario. Questo sarà incluso se il tempo e le risorse lo consentiranno. | Ridotto interesse per il dataset da parte della collettività. Pubblicato da qualche PA |
| W - WON’T | Indica un dataset che che non sarà inserito nella lista di pubblicazione attuale, ma che può essere considerato per il futuro. | Non si riscontra interesse per il dataset da parte della collettività. Non sono stati pubblicati dataset simili in altre PA |
Tale metodo è stato usato dal Team Open Data nelle riunioni periodiche e aperte al pubblico dal dicembre 2015 al dicembre 2016 per l’individuazione dei dataset tematici da pubblicare. Con cadenza annuale ogni Dirigente provvederà, se necessario, all’aggiornamento dell’elenco delle raccolte di dati di sua competenza.
L’attività di individuazione dei dati oggetto di pubblicazione in formato aperto dovrà essere, in ogni caso, condotta in modo tale da escludere quelli che, per il tipo di riutilizzo o per le modalità con cui si intende realizzarlo, potrebbero violare:
- la sicurezza pubblica, la difesa nazionale, lo svolgimento di indagini penali o disciplinari;
- il diritto di terzi al segreto industriale, statistico e commerciale, o altri vincoli di segretezza fissati in obblighi di legge;
- i diritti di proprietà intellettuale;
- il diritto alla protezione dei dati personali.
In ogni caso, per assicurare la trasparenza amministrativa garantendo, al contempo, la protezione dei dati personali o coperti da segreto, il Comune procederà, quando necessario, alla pubblicazione di dati aggregati o resi anonimi in modo da non consentire alcuna identificazione, nemmeno indiretta, dei soggetti a cui tali dati si riferiscono, coerentemente con la normativa vigente in materia.
Modalità di produzione dei dataset e formato di pubblicazione¶
(In parte da “Allegato B - Formati aperti e metadati per il riutilizzo e la diffusione dei dati pubblici” della Provincia di Trento) Il Comune di Palermo metterà a disposizione i dati pubblici, ove possibile, in modalità elettronica e nei seguenti formati aperti che favoriscano l’interoperabilità:
| Nome (Acronimo) - Descrizione | Tipo di Dato | Estensione del file |
|---|---|---|
| Comma Separated Value (CSV) - Formato testuale per l’interscambio di tabelle, le cui righe corrispondono a record e i cui valori delle singole colonne sono separati da una virgola (o punto e virgola) | Dato tabellare | .csv |
| Geographic Markup Language (GML) - Formato XML utile allo scambio di dati territoriali di tipo vettoriale | Dato geografico vettoriale | .gml |
| GeoJSON - E’ un formato di testo aperto, per la codifica di oggetti geografici e dei correlati attributi non spaziali, scritto in JSON (JavaScript Object Notation). | Dato geografico vettoriale | Di solito .geojson, .topojson, o .json |
| Keyhole Markup Language (KML) - Formato basato su XML creato per gestire dati territoriali in tre dimensioni. | Dato geografico vettoriale | .kml |
| Open Document Format per dati tabellari (ODS) - Formato per l’archiviazione e lo scambio di fogli di calcolo | Dato tabellare | .ods |
| Resource Description Framework (RDF) - Basato su XML, e’ lo strumento base proposto da World Wide Web Consortium (W3C) per la codifica, lo scambio e il riutilizzo di metadati strutturati e consente l’interoperabilità tra applicazioni che si scambiano informazioni sul Web | Dato strutturato | .rdf |
| ESRI Shapefile (SHP) - Lo Shapefile ESRI è un popolare formato vettoriale per sistemi informativi geografici. Il dato geografico viene distribuito normalmente attraverso tre o quattro files (se indicato il sistema di riferimento delle coordinate). Il formato è stato rilasciato da ESRI come formato (quasi) aperto | Dato geografico vettoriale | .shp, .shx, .dbf, .prj |
| Tab Separated Value (TSV) - Formato testuale per l’interscambio di tabelle, le cui righe corrispondono a record e i cui valori delle singole colonne sono separati da un carattere di tabulazione | Dato tabellare | .tsv |
| Extensible Markup Language (XML) - E’ un formato di markup, ovvero basato su un meccanismo che consente di definire e controllare il significato degli elementi contenuti in un documento o in un testo attraverso delle etichette (markup) | Dato strutturato | .xml |
I dati saranno resi disponibili da ciascuna Area in un formato aperto che li renda riutilizzabili direttamente da programmi di elaborazione di calcolo da parte di una macchina (formato machine-readable) e, ove possibile, in formato standard pubblici, leggibili e basati su specifiche pubbliche ed esaustive tali da permetterne l’interpretazione da parte di persone (formati human-readable). I dati saranno resi disponibili accompagnati dai relativi metadati, salvo specifiche e motivate eccezioni, indicate per ciascun dataset da ciascuna Area nell’ambito dell’individuazione periodica dei dati che saranno rilasciati in formato aperto, secondo quanto indicato al punto precedente delle presenti Linee Guida.
Modalità di produzione dei dataset dalle piattaforme ICT del PON METRO Palermo¶
Il PON METRO Palermo è un programma di interventi che, tra gli altri, prevede, dal 2017 al 2020, la realizzazione di 7 piattaforme digitali tematiche che riguardano i seguenti ambiti: ambiente e territorio, lavoro e formazione, tributi, edilizia e catasto, cultura e tempo libero, assistenza e sostegno sociale, lavori pubblici. Al momento della redazione delle presenti linee guida comunali open data, l’Amministrazione comunale ha avviato la progettazione esecutiva propedeutica alla realizzazione delle piattaforme ICT alle quali saranno agganciati i processi amministrativi e i servizi degli uffici/aree competenti. Al fine di ottimizzare la generazione e pubblicazione dei dataset in open data concernenti le tematiche delle piattaforme digitali del PON METRO, e al fine di stimolarne il riuso, si ritiene valido strutturare le stesse in maniera tale da ospitare, e quindi rendere disponibili, le API (Application Programming Interface) per ogni tipologia di riuso creativo, sia interno all’Amministrazione o esterno da parte della società.
I Metadati con il profilo nazionale DCAT_AP_IT¶
I dati aperti pubblicati attualmente dal Comune di Palermo utilizzano lo schema di metadati definito nelle precedenti linee guida comunali. In accordo con le linee guida nazionali per la valorizzazione del patrimonio informativo pubblico è necessario recepire le indicazioni relativo all’utilizzo del profilo nazionale DCAT-AP_IT.
Nel caso di dati geografici il profilo di metadatazione da adottare è quello del Repertorio Nazionale dei Dati Territoriali (RNDT), conforme alla direttiva INSPIRE.
In aggiunta, l’insieme dei metadati del profilo DCAT-AP_IT è stato integrato con metadati aggiuntivi ritenuti rilevanti per migliorare il riuso dei dati pubblicati, come già previsto dalle linee guida nazionali: «Le pubbliche amministrazioni possono integrare i metadati previsti dal modello DCAT-AP_IT con metadati aggiuntivi, secondo le proprie necessità seppur nel pieno rispetto delle regole di conformità come definite nella specifica DCAT-AP_IT».
Questa sezione, non ha lo scopo di approfondire i dettagli tecnici della specifica DCAT-AP_IT, già ampiamente discussi nei documenti ufficiali, ma si focalizza su due aspetti specifici che riguardano l’introduzione della specifica DCAT-AP_IT nel contesto della pubblicazione dei dati aperti del comune di Palermo. Nello specifico in questa sezione verranno presentate: a) le relazioni tra i metadati della specifica DCAT-AP_IT e lo schema di metadati adottato fino adesso, in accordo alla precedente versione delle linee guida comunali, al fine di consentire l’adeguamento dei metadati già pubblicati, al profilo nazionale della specifica DCAT-AP_IT; b) le integrazioni adottate dal comune di Palermo ai metadati della specifica DCAT-AP_IT.
La specifica DCAT-AP_IT propone una struttura di metadati, basata sui concetti principali di Catalogo, Dataset e Distribuzione. Il Catalogo rappresenta un insieme di dataset, e pertanto i metadati relativi ad esso riguardano le proprietà dell’intero insieme di dataset (es. Organizzazione che pubblica i dati). Al Catalogo sono associati i Dataset che lo compongono. A sua volta ogni Dataset, può avere a sé associate diverse Distribuzioni, che si differenziano per il formato usato per la pubblicazione dei dati, la licenza utilizzata, e così via. Ogni Distribuzione prevede quindi metadati specifici per descrivere queste proprietà. Relativamente al catalogo, la versione attuale delle linee guida non prevede dei metadati specifici per l’intero catalogo, pertanto per rendere la pubblicazione dei dati conforme alle specifiche DCAT-AP_IT i metadati relativi al catalogo dovranno essere resi disponibili. La seguente tabella riporta i metadati previsti dalla specifica DCAT-AP_IT per la descrizione del Catalogo.
Metadati per la descrizione del Catalogo (dcatapit:Catalog) (*Obbligatorio)
| Metadato | Proprietà DCAT_AP_IT | Descrizione |
|---|---|---|
| titolo del catalogo* | dct:title (M) | Questa proprietà contiene un nome dato al Catalogo. Questa proprietà può essere ripetuta per esprimere il titolo in diverse lingue. |
| descrizione catalogo* | dct:description (M) | Questa proprietà contiene una sintesi con un testo libero delle caratteristiche del catalogo. Questa proprietà può essere ripetuta per esprimere la descrizione in diverse lingue. |
| home page catalogo | foaf:homepage (R) | Questa proprietà si riferisce ad una pagina web che funge da pagina principale per il Catalogo. |
| lingua catalogo | dct:language (R) | Questa proprietà si riferisce a una lingua utilizzata nei metadati testuali che descrivono i titoli, le descrizioni, … dei Dataset nel Catalogo. Questa proprietà può essere ripetuta se i metadati sono forniti in più lingue. Deve essere utilizzato il vocabolario http://bit.ly/2tWLEJd |
| temi del catalogo | dcat:themeTaxonomy (R) | Questa proprietà si riferisce ad un sistema di organizzazione della conoscenza (KOS) usato per classificare i dataset del Catalogo. Il valore da utilizzare per questa proprietà è l’URI del vocabolario stesso (non gli URI dei concetti presenti nel vocabolario). Nel caso del vocabolario EU Data Theme da utilizzare obbligatoriamente per indicare i temi relativi ai Dataset, l’URI da indicare è il seguente http://bit.ly/2tKxGK0 |
| editore del catalogo* | dct:publisher (M) | Questa proprietà si riferisce ad un’entità (organizzazione) responsabile a rendere disponibile il Catalogo. |
| data rilascio catalogo | dct:issued (R) | Questa proprietà contiene la data del rilascio formale (es. pubblicazione) del Catalogo. |
| data ultima modificacatalogo | dct:modified (R) | Questa proprietà contiene la data più recente in cui il Catalogo è stato aggiornato. |
I metadati definiti nella precedente versione delle linee guida, e attualmente in uso, trovano corrispondenze nelle proprietà degli elementi Dataset e Distribuzione nello schema DCAT-AP_IT. Le seguenti tabelle riportano, i dati obbligatori per lo schema DCAT-AP_IT (indicati con M), quelli ritenuti obbligatori secondo lo schema proposto da queste linee guida (asterisco * ). Si fa presente che si è scelto di mantenere obbligatori i metadati indicati come tali nella precedente versione delle linee guida anche se lo schema DCAT-AP_IT non lo prevede.
Come nomi delle proprietà dei metadati si è scelto di adottare quello proposto dallo schema DCAT-AP_IT. Nelle seguenti tabelle viene riportato in corsivo tra parentesi il nome corrispondente nello schema di metadati adottato dalle precedenti linee guida.
Metadati per la descrizione del Dataset (dcatapit:Dataset) (*Obbligatorio)
| Metadato | Proprietà DCAT-AP_IT | Descrizione |
|---|---|---|
| Titolo* | dct:title (M) | Questa proprietà contiene un nome assegnato al Dataset. Questa proprietà può essere ripetuta per esprimere il titolo in diverse lingue |
| Descrizione* | dct:description (M) | Questa proprietà contiene una sintesi come testo libero delle caratteristiche del Dataset. Questa proprietà può essere ripetuta per esprimere la descrizione in diverse lingue. |
| punto di contatto (Contatto)* | dcat:contactPoint (R) | Questa proprietà contiene informazioni di contatto che possono essere usate per inviare osservazioni e commenti sul Dataset. |
| tema del dataset (Categorie)* | dcat:theme (R) | Questa proprietà si riferisce alla categoria in cui è classificato il Dataset. Un Dataset può essere associato a più temi. I valori da utilizzare per questa proprietà sono gli URI dei concetti del vocabolario EU Data Theme (URI vocabolario: http://publications.europa.eu/resource/authority/data-theme) descritti alla pagina http://publications.europa.eu/mdr/authority/data-theme |
| titolare del dataset (Assessorato titolare)* | dct:rightsHolder | Sulla base anche di quanto indicato all’art.2 lettera i) del D. Lgs. n. 36/2006, il titolare del dataset è la pubblica amministrazione o l’organismo di diritto pubblico che ha originariamente formato per uso proprio o commissionato ad altro soggetto pubblico o privato il documento che rappresenta il dato, o che ne ha la disponibilità. Il titolare è pertanto responsabile della gestione complessiva del dataset in virtù dei propri compiti istituzionali. Si fa presente che, nell’ambito della presente specifica, l’accezione di documento suddetta può essere intesa riferita al dataset. |
| frequenza di aggiornamento (aggiornamento)* | dct:accrualPeriodicity (O) | Questa proprietà si riferisce alla frequenza con cui il Dataset viene aggiornato. I valori da utilizzare per questa proprietà sono gli URI dei concetti del vocabolario MDR Frequency Named Authority List http://publications.europa.eu/mdr/authority/frequency |
| data di rilascio (Data di pubblicazione)* | dct:issued (O) | Questa proprietà contiene la data del rilascio formale (es. pubblicazione) del Dataset. |
| data di ultima modifica (Data di aggiornamento)* | dct:modified (O) | Questa proprietà contiene la data più recente in cui il Dataset è stato modificato o aggiornato |
| autore del dataset (Autore) | dct:creator | Questa proprietà si riferisce a una o più entità (organizzazione) che hanno materialmente creato il Dataset. Nel caso in cui titolare e autore del dataset coincidano, allora si può omettere questa proprietà. (Le informazioni relative all’autore possono anche includere l’email o l’indirizzo dell’organizzazione) |
| copertura Geografica | dct:spatial (O) | Questa proprietà si riferisce a un’area geografica coperta dal Dataset. (Vanno specificati i metadati di Localizzazione (dct:Location) così come indicati nella specifica DCAT-PA_IT) |
| estensione temporale | dct:temporal (O) | Questa proprietà si riferisce a un periodo temporale coperto dal Dataset. (Vanno specificati: data iniziale e data finale) |
| Referente* | E’ il titolare del dataset, cioé il “titolare della banca dati” come definito sopra (nel paragrafo sulla strutturazione interna) | |
| Dataset richiesto da un cittadino | Booleano si/no | |
| Documentazione tecnica | Indirizzo o indirizzi delle pagine web che contengono informazioni utili alla comprensione del contenuto del dataset | |
| Altro | Ogni altra informazione utile per dataset |
Metadati per la descrizione della Distribuzione (dcatapit:Distribution) associata al Dataset (* Obbligatorio)
| Metadato_IT | Proprietà DCAT-AP | Descrizione |
|---|---|---|
| URL di accesso* (URI permanente) | dcat:accessURL (M) | Questa proprietà contiene un URL tramite cui si può accedere alla Distribuzione del Dataset. |
| Licenza* | dct:license (R) | Questa proprietà si riferisce a una licenza con la quale la Distribuzione è resa disponibile. |
| formato distribuzione (Formato)* | dct:format (R) | Questa proprietà si riferisce al formato del file della Distribuzione. I valori da utilizzare per questa proprietà sono gli URI dei concetti del vocabolario MDR File Type Named Authority List http://publications.europa.eu/mdr/authority/file-type. Nel caso di file “nidificati” (i.e. file compressi), il formato da indicare è quello originario e non quello della cartella compressa che contiene il file originario. Per esempio, nel caso del file nomefile.ttl.bz2, il formato da indicare è .ttl e non .bz2. |
| lunghezza del file /dimensione in byte (Dimensione) | dcat:byteSize (O) | Questa proprietà contiene la lunghezza della Distribuzione in byte. |
| Codifica Caratteri | Codifica dei caratteri utilizzata (es. “latin-1”, “PC-850”) | |
| Formato distribuzione richiesto da un cittadino |
L’introduzione del nuovo schema dei metadati non comporta sostanziali modifiche allo schema di metadati fino adesso adottato. I principali cambiamenti riguardano: a) i nomi delle proprietà; b) l’URL di accesso ai dati che con l’adozione di DCAT-AP_IT diviene obbligatorio (Poiché l’URL di accesso è disponibile per tutti dati attualmente pubblicati, questa modifica potrà essere applicata senza particolari problemi), c) dal punto di vista implementativo i metadati dovranno essere resi disponibili in maniera conforme a quanto specificato dal DCAT-AP_IT.
Confrontando lo schema di metadati adottato dal comune di Palermo con la specifica DCAT-AP_IT si evidenzia che: tutte le proprietà obbligatorie (M) e raccomandate (R) in DCAT-AP_IT sono state indicate come obbligatorie. Alcune proprietà (come frequenza di aggiornamento, data di rilascio) sono state ritenute di notevole importanza e pertanto vengono richieste come obbligatorie anche se in DCAT-AP_IT sono opzionali. Inoltre, sono state previste alcune integrazioni allo schema DCAT-AP_IT sia per i Dataset che per le Distribuzioni. Relativamente al Dataset sono state integrate come opzionali le proprietà che permettono di indicare se il dataset è stato richiesto da un cittadino, se c’è una documentazione tecnica allegata, ed eventuali note. In aggiunta, viene mantenuta come obbligatoria la proprietà Referente, anche se essa non è presente in DCAT-AP_IT. Per quanto riguarda la Distribuzione, è stata integrata come opzionale la proprietà relativa alla codifica dei caratteri, e anche in questo caso, si potrà indicare tra i metadati se il formato di distribuzione è stato richiesto da un cittadino.
Infine, una considerazione particolare va riportata per le licenze. La specifica DCAT-AP_IT, infatti, richiede ulteriori informazioni sui metadati relativi alla licenza delle distribuzioni, come indicato nella seguente tabella.
Metadati per la descrizione della Licenza (dcatapit:LicenceDocument) (*Obbligatorio)
| Metadato | Proprietà DCAT-AP_IT | Descrizione |
|---|---|---|
| tipo licenza* | dct:type (R) | Questa proprietà si riferisce al tipo di licenza, per es. che indica “pubblico dominio” o “richiesto pagamento diritti”. I valori da utilizzare per questa proprietà sono gli URI dei concetti del vocabolario “ADMS licence type vocabulary” (http://purl.org/adms/licencetype/). L’elenco dei termini del vocabolario indicato è incluso nella specifica ADMS. |
| identificativo | dct:identifier | Questa proprietà contiene un identificativo della Licenza, per es. l’URI o altro identificativo univoco. Si raccomanda di utilizzare come valori per questa proprietà gli URI delle licenze del vocabolario raccomandato http://creativecommons.org/ns#Work |
| nome | foaf:name | Questa proprietà contiene un nome assegnato alla Licenza. Si raccomanda di fare riferimento al vocabolario indicato per la proprietà Identificativo. |
| versione | owl:versionInfo | Questa proprietà contiene il numero della versione o Altre indicazioni della versione della Licenza. |
Modello di dati per i dati aperti¶
(Linee Guida Nazionali per la Valorizzazione del Patrimonio Informativo Pubblico, Anno 2016, AgID). Si adotta il modello qualitativo per i dati aperti sul Web, noto come modello a cinque stelle. In particolare, si tende a seguire un percorso graduale verso la produzione nativa di Linked Open Data – LOD (livello cinque stelle), iniziando dal livello 3. Produzione e pubblicazione di dati aperti solo di livello 1 e 2 non sono più ammessi: quest’ultimi devono essere accompagnati da quelli che rispecchiano le caratteristiche dei livelli 3 e/o superiori (per esempio, rilasciare dati strutturati solo in excel con licenza aperta non è ammesso; questi devono essere sempre affiancati da dati strutturati in formato non proprietario).
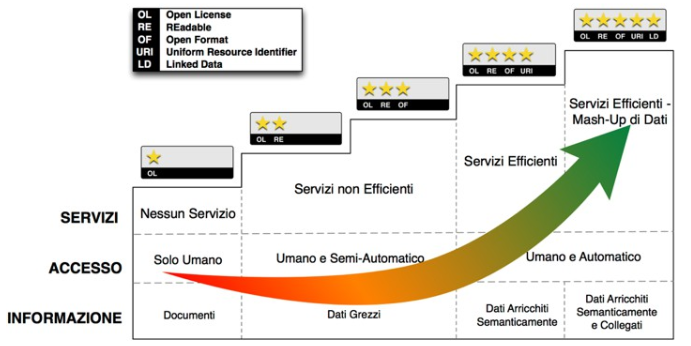
(★) 1 Stella.
- Informazione:
- Dati disponibili tramite una licenza aperta e inclusi in documenti leggibili e interpretabili solo grazie a un significativo intervento umano (e.g., PDF).
- Accesso:
- Prevalentemente umano, necessario anche per dare un senso ai dati inclusi nei documenti.
- Servizi:
- Solo rilevanti interventi umani di estrazione ed elaborazione dei possibili dati consentono di sviluppare servizi con l’informazione disponibile in questo livello.
(★★) 2 Stelle.
- Informazione:
- Dati disponibili in forma strutturata e con licenza aperta. Tuttavia, i formati sono proprietari (e.g., Excel) e un intervento umano è fortemente necessario per un’elaborazione dei dati.
- Accesso:
- I programmi possono elaborare i dati ma non sono in grado di interpretarli; pertanto è necessario un intervento umano al fine di scrivere programmi ad-hoc per il loro utilizzo.
- Servizi:
- Servizi ad-hoc che devono incorporare i dati per consentire un accesso diretto via Web agli stessi.
(★★★) 3 Stelle.
- Informazione:
- Dati con caratteristiche del livello precedente ma in un formato non proprietario (e.g., CSV, JSON, geoJSON). I dati sono leggibili da un programma ma l’intervento umano è necessario per una qualche elaborazione degli stessi.
- Accesso:
- I programmi possono elaborare i dati ma non sono in grado di interpretarli; pertanto è necessario un intervento umano al fine di scrivere programmi ad-hoc per il loro utilizzo.
- Servizi:
- Servizi ad-hoc che devono incorporare i dati per consentire un accesso diretto via Web agli stessi.
(★★★★) 4 Stelle.
- Informazione:
- Dati con caratteristiche del livello precedente ma esposti usando standard W3C quali RDF e SPARQL I dati sono descritti semanticamente tramite metadati e ontologie.
- Accesso:
- I programmi sono in grado di conoscere l’ontologia di riferimento e pertanto di elaborare i dati quasi senza ulteriori interventi umani.
- Servizi:
- Servizi, anche per dispositivi mobili, che sfruttano accessi diretti a Web per reperire i dati di interesse.
(★★★★★) 5 Stelle.
- Informazione:
- Dati con caratteristiche del livello precedente ma collegati a quelli esposti da altre persone e organizzazioni (i.e., Linked Open Data [1]). I dati sono descritti semanticamente tramite metadati e ontologie. Essi seguono il paradigma RDF (si veda “Architettura dell’informazione del settore pubblico”), in cui alle “cose” (o entità) è assegnata un URI univoca sul Web. Conseguentemente tale URI può essere utilizzata per effettuare accessi diretti alle informazioni relative a quella entità. I dati sono detti «linked» per la possibilità di referenziarsi (i.e., «collegarsi») tra loro. Nel referenziarsi, si usano relazioni («link») che hanno un preciso significato e spiegano il tipo di legame che intercorre tra le due entità coinvolte nel collegamento. I Linked (Open) Data sono quindi un metodo elegante ed efficace per risolvere problemi di identità e provenienza, semantica, integrazione e interoperabilità. Triple RDF i cui URI non siano utilizzabili da un agente Web per recuperare le informazioni a essi associati, non possono essere considerati pienamente conformi al paradigma Linked Data. Nei caso dei Linked Open Data l’intervento umano si può ridurre al minimo e talvolta addirittura eliminare.
- Accesso:
- I programmi sono in grado di conoscere l’ontologia di riferimento e pertanto di elaborare i dati quasi senza ulteriori interventi umani.
- Servizi:
- Servizi, anche per dispositivi mobili, che sfruttano sia accessi diretti a Web sia l’informazione ulteriore catturata attraverso i «link» dei dati di interesse, facilitando il mashup di dati.
Note
| [1] | https://www.ted.com/talks/tim_berners_lee_on_the_next_web?nolanguage=en%2C https://www.w3.org/DesignIssues/LinkedData.html |
I livelli del modello per i metadati¶
(Linee Guida Nazionali per la Valorizzazione del Patrimonio Informativo Pubblico, Anno 2016, AgID). La metadatazione ricopre un ruolo essenziale laddove i dati sono esposti a utenti terzi e a software. I metadati, infatti, consentono una maggiore comprensione e rappresentano la chiave attraverso cui abilitare più agevolmente la ricerca, la scoperta, l’accesso e quindi il riuso dei dati stessi. A tale scopo, si adotta il modello per i metadati rappresentato in figura. Il modello si focalizza sugli aspetti qualitativi dei metadati, è indipendente dal particolare schema proposto e, in parte, anche dal formato fisico di rappresentazione. La classificazione qualitativa dei metadati si fonda su due fattori principali: legame tra dato-metadato e livello di dettaglio.
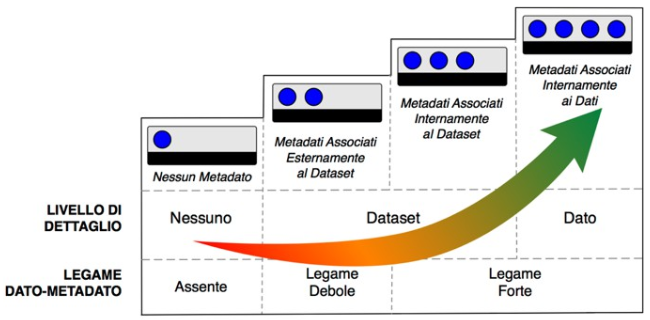
Fig. 1 Modello a quattro livelli per i metadati
1° livello
- Legame dato metadato:
- Nessun legame in quanto i dati non sono accompagnati da un’opportuna metadatazione.
- Livello di dettaglio:
- Nessuno in quanto i metadati non sono presenti.
2° livello
- Legame dato metadato:
- Il legame è debole perché i dati sono accompagnati da metadati esterni, (e.g., inclusi nella pagina di download del dataset o in file separati).
- Livello di dettaglio:
- I metadati forniscono informazioni relativamente a un dataset, quindi sono informazioni condivise dall’insieme di dati interni a quel dataset.
3° livello
- Legame dato metadato:
- Il legame è forte perché i dati incorporano i metadati che li descrivono.
- Livello di dettaglio:
- I metadati forniscono informazioni relative a un dataset, quindi sono informazioni condivise dall’insieme di dati interni a quel dataset.
4° livello
- Legame dato metadato:
- Il legame è forte perché i dati incorporano i metadati che li descrivono.
- Livello di dettaglio:
- I metadati forniscono informazioni relative al singolo dato, quindi col massimo grado di dettaglio possibile
Licenza per il riutilizzo¶
Per gli aspetti legati alle licenze da assegnare ad ogni dataset si fa riferimento al paragrafo “Aspetti legali e di costo “ delle linee guida nazionali per la valorizzazione del patrimonio informativo pubblico (AgID 2016). Sulla piattaforma predisposta per il rilascio dei dati saranno presenti e facilmente identificabili le informazioni relative alle licenze adottabili.
Frequenza di aggiornamento¶
Periodicamente, con cadenza almeno annuale stabilita e formalizzata dal team Open Data in relazione alla tipologia di dati, i singoli Settori provvederanno all’aggiornamento dei dati già disponibili e oggetto di riutilizzo. Deve essere previsto nella pagina del dataset la comparsa di un alert nel caso la frequenza di aggiornamento non venga rispettata.
Modalità di pubblicazione dei dataset sul sito web¶
Le raccolte di dati verranno pubblicate secondo le priorità attribuite dal team Open Data.
Le raccolte di dati vengono pubblicate nella sezione “Open Data” del sito web del Comune di Palermo con i relativi metadati.
Le raccolte di dati sono pubblicate e attribuite a una o più delle seguenti tematiche:
- AMBIENTE
- AMMINISTRAZIONE
- CULTURA E TURISMO
- DATI SUL TERRITORIO
- ISTRUZIONE
- MOBILITA” E SICUREZZA
- OPERE PUBBLICHE
- SANITA” E SOCIALE
- URBANISTICA
- ATTIVITA” ECONOMICHE
- BILANCIO
- ELEZIONI
Le tematiche possono essere riviste annualmente e aggiornate, se necessario, dal team Open Data o dal Webmaster in ragione delle nuove necessità sopraggiunte.
Comunicazione e promozione dei dataset pubblicati¶
Il Responsabile Open Data con il suo staff supporta, sul piano formativo e tecnologico, i Settori/Uffici e le altre strutture comunali nell’intero processo di formazione dei dati, in modo da garantirne la coerenza con gli standard necessari alla loro piena fruibilità e apertura.
Il Responsabile Open Data con il suo staff supporta iniziative private e pubbliche (Incontri, Barcamp, Hackathons, Mappathon, Open Data day, …) volte alla comunicazione e promozione dell’ecosistema Open Data, incoraggiando, sostenendo o promuovendo attività volte alla conoscenza ed all’uso dei dataset pubblicati nel sistema.